
Neighborhoods.com • Cross-Service Integrations
REST workflows • Contracts • Reliability patterns • Ecosystem unlock
Service integrations designed like a platform contract
Delivered cross-service integrations that unlocked new capabilities across the ecosystem: consistent APIs, reliable workflows, and safe retries—built to handle partial failure and scale without creating “brittle spaghetti.”
Pattern: Contract-first REST
Reliability: Idempotent ops
Ops: Observability built in
Outcome: Ecosystem unlocks
Integration playbook (high-level)
Contract
- Request/response schemas
- Error codes and semantics
- Versioning strategy
- SLAs + ownership
Workflow
- Idempotency keys
- Retries with backoff
- Compensation behavior
- Timeout budgets
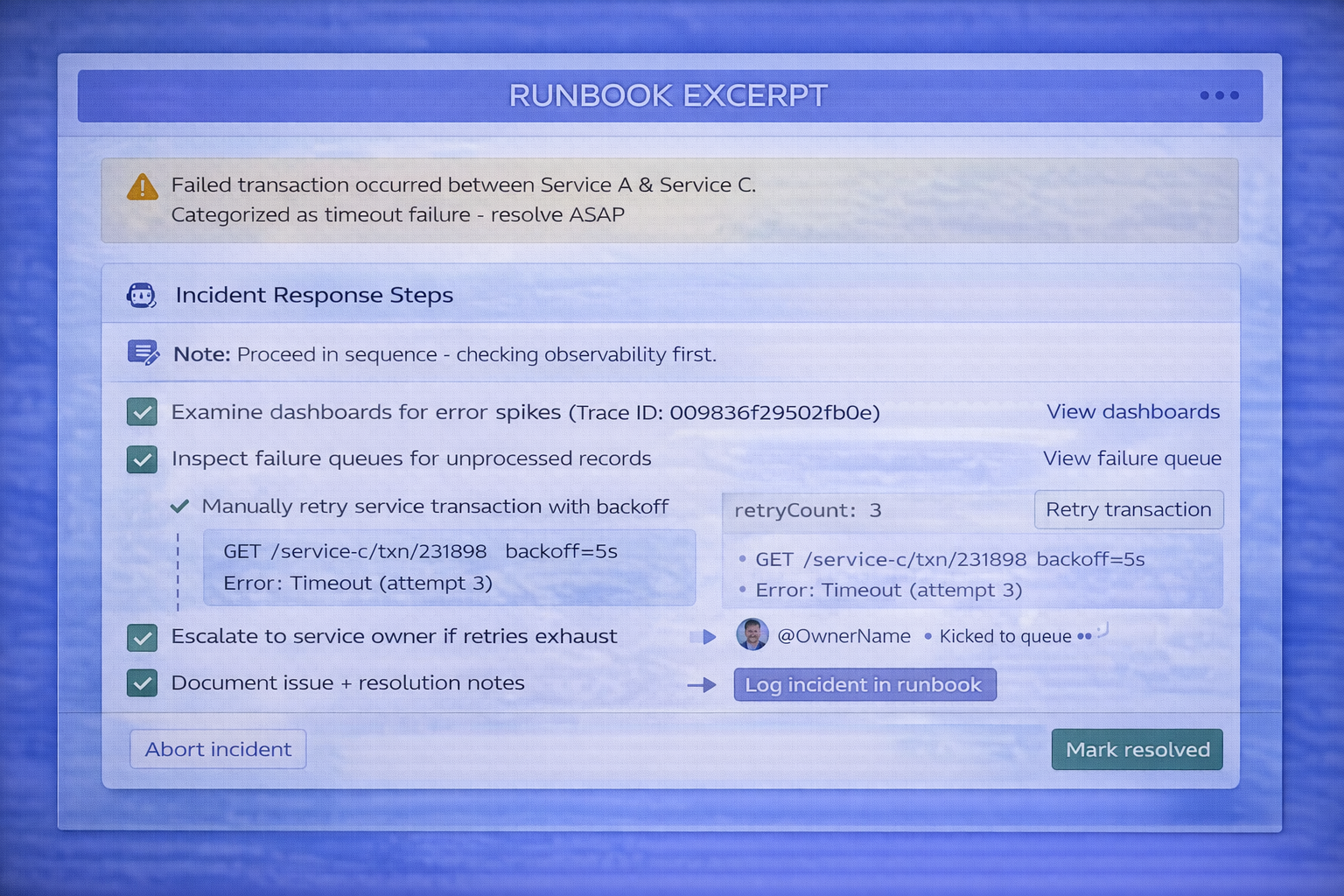
Observability
- Tracing identifiers
- Dashboards and alerts
- Failure queues
- Runbooks
Core services
0+
6
Integration types
0+
Sync + async + webhooks.
Failure handling
Designed
Partial failure accounted for up front.
API posture
Versioned
Backwards compatible changes by default.
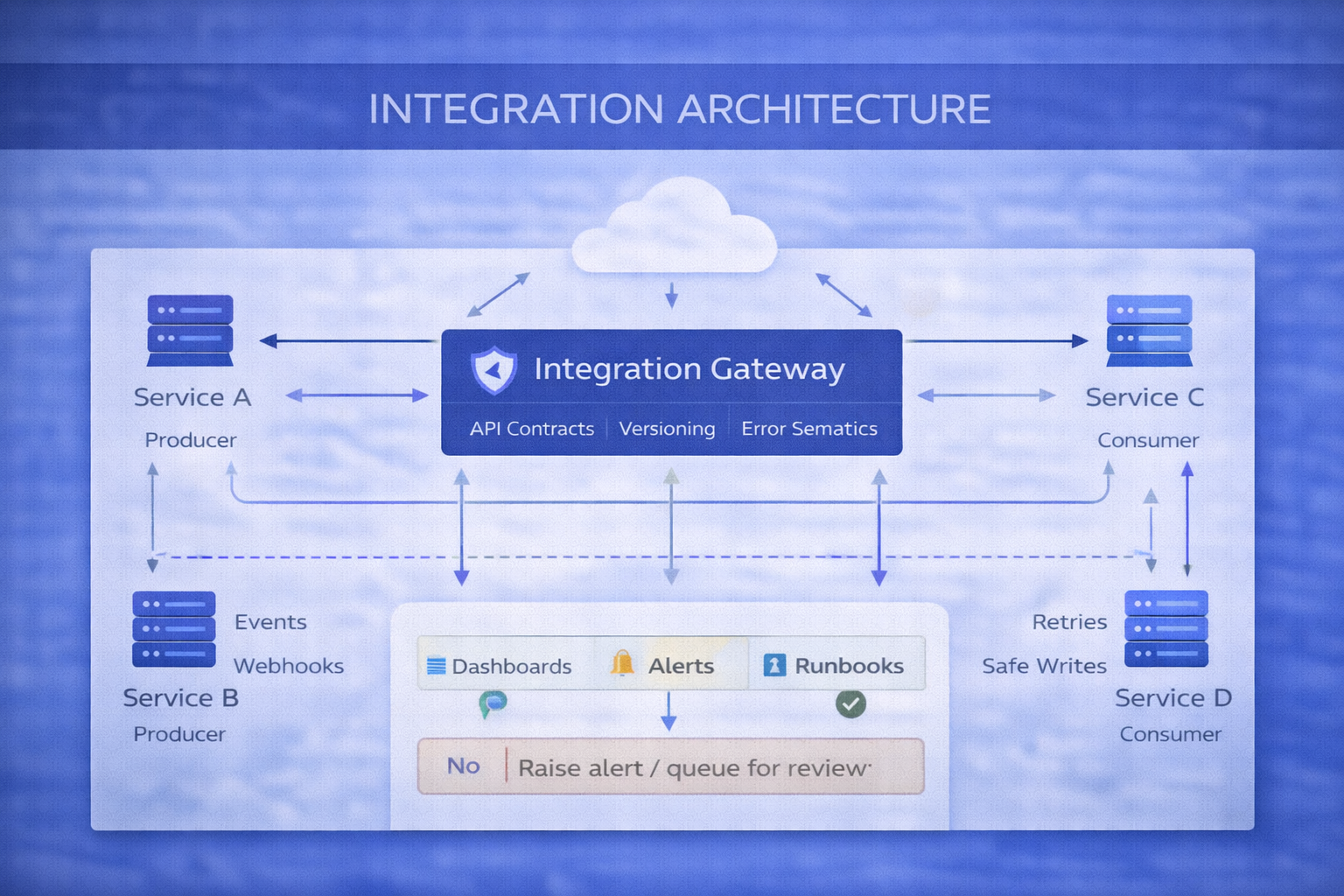
System map (interactive)
Integration Gateway + Contracts
Standard schemas + versioned APIs
Service A
Producer + ownership boundaries
Service B
Consumer + failure-aware behavior
Observability + Runbooks
Trace + alert + respond
Integration Gateway + Contracts
API contract table
| Contract | Definition | Versioning rule |
|---|---|---|
| Resource schema | Explicit request/response schema with required fields and defaults. | Additive changes default; breaking changes require version bump. |
| Error semantics | Standard error shape and codes with retry guidance. | Never change meaning of existing error codes. |
| Idempotency | Writes include idempotency keys and deterministic behavior. | Keys stable across retries and replays. |
| Rate limits | Documented and enforced to protect systems. | Increases allowed; decreases require migration period. |
Integration test coverage
Contract tests
- Schema validation
- Required fields
- Error shapes
Workflow tests
- Retries
- Timeout budgets
- Compensation
Observability tests
- Trace IDs present
- Metrics emitted
- Alert thresholds
Reliability patterns
| Failure mode | Design response | User impact control |
|---|---|---|
| Timeouts | Retries with backoff; timeout budgets per hop. | Graceful fallback + queued retry |
| Partial failure | Compensation steps or reconciliation jobs. | Eventual consistency messaging |
| Duplicate requests | Idempotency keys and deterministic writes. | No double-actions / no double billing |
| Breaking schema change | Versioned endpoints and compatibility layer. | Prevent outages across teams |
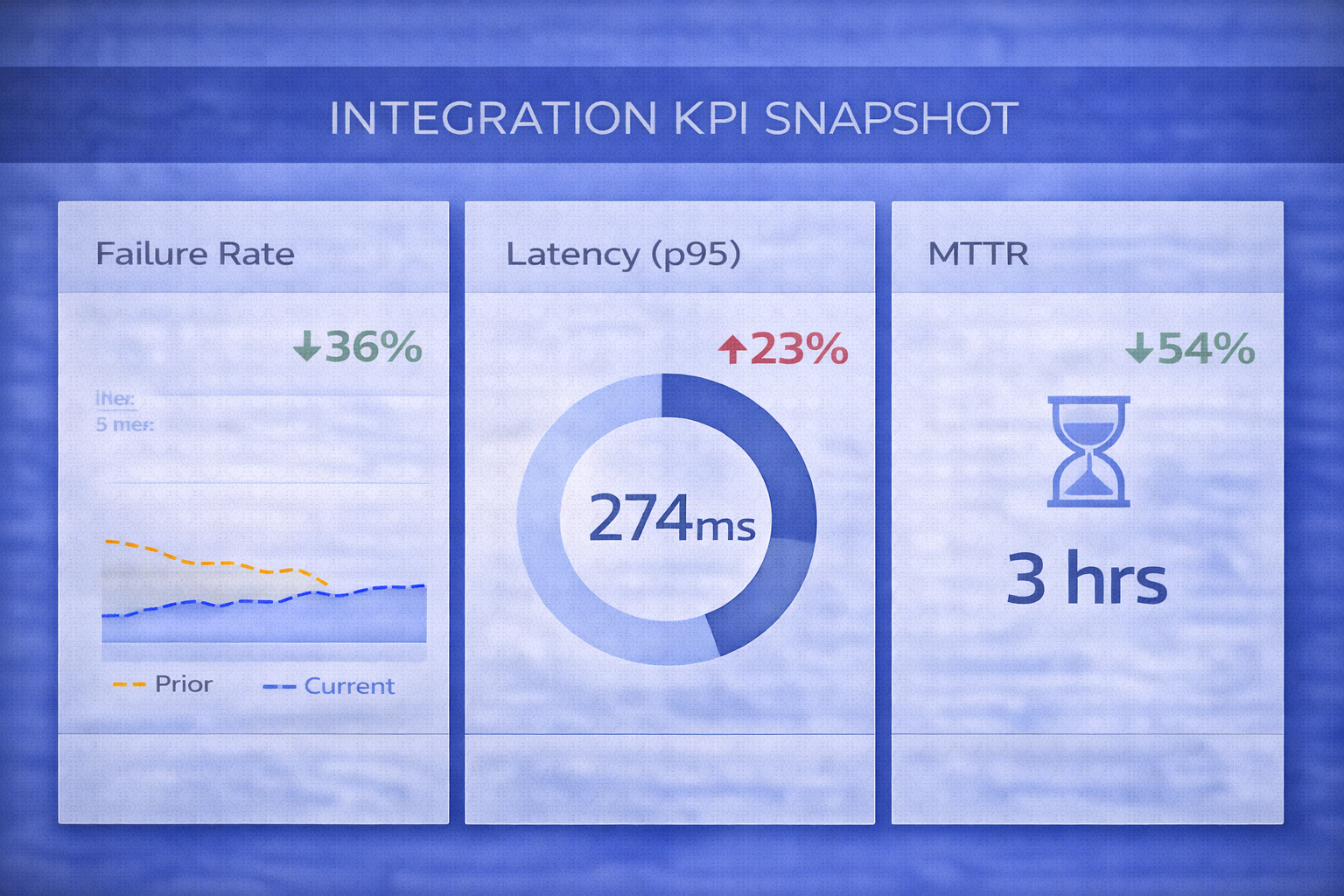
Impact (replace with your metrics)
| Outcome | What improved |
|---|---|
| New capabilities shipped | Teams could build cross-product features without bespoke one-offs. |
| Reduced integration failures | Idempotency and retries reduced incident rates for workflows. |
| Faster debugging | Trace IDs and dashboards reduced time-to-diagnose across hops. |
| Safer change management | Versioning strategy reduced breaking-change outages. |
My leadership
How I led
- Drove contract-first thinking and clear ownership boundaries.
- Designed reliability patterns as requirements, not “nice-to-haves.”
- Aligned teams around shared schemas, versioning, and observability standards.
- Created integration playbooks and runbooks for repeatable delivery.
Best-practice highlights
- Versioned API contracts and compatibility strategy
- Idempotency keys for write operations
- Failure-aware workflows and compensation
- Observability built into integration design
© Case Study • Neighborhoods.com • Cross-Service Integrations